JPA saveAll과 JdbcTemplate batchUpdate 성능 비교 (허접함 주의)
서론
Spring + JPA를 사용해 진행 중인 프로젝트에서 bulk insert가 필요한 상황이 생겼다.
bulk라기엔 민망한 최대 300개 데이터이긴 하지만, JpaRepository의 saveAll 메서드를 호출해 저장 시 300개의 insert 쿼리가 따로 나간다는 점이 조금 마음에 걸렸다.
사실상 saveAll은 사용하지 말자는 것은 정해진 듯 보였고, 다음 고민거리는 대체자로 무엇을 사용할 것인가였다.
가장 일반적으로 사용되는 대안은 JdbcTemplate이었으나, 아예 문자열로 쿼리를 박아버리는 방식 자체가 찝찝해 다른 방법이 있는지 찾아보고 있던 상황이었다.
그러던 중 친구랑 나눈 대화가 실험욕구를 자극했다.

본론
그래서 JPARepository.saveAll과 JdbcTemplate.batchUpdate를 직접 비교해보았다.
테스트는 어떻게 보면 매우 간단하고, 어떻게 보면 매우 허접하다.
특정 개수의 객체를 데이터베이스에 저장하는데 있어서, JPARepository의 saveAll 메서드를 호출하는 경우와 JdbcTemplate의 batchUpdate를 사용하는 것 사이에 어느 정도의 시간차이가 존재하는지 확인한다.
우선 테스트를 위해 사용할 Book 객체를 간단히 만들어주었다.
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long no;
private String title;
private String content;
private String writer;
private LocalDateTime createdAt;
public Book(String title, String content, String writer, LocalDateTime createdAt) {
this.title = title;
this.content = content;
this.writer = writer;
this.createdAt = createdAt;
}
}
JpaRepository를 extends하는 BookRepository 객체를 정의하고
public interface BookRepository extends JpaRepository<Book, Long> {
}
JdbcTemplate을 사용하는 JdbcBookRepository 객체 또한 정의해주었다.
@RequiredArgsConstructor
@Repository
public class JdbcBookRepository {
private final JdbcTemplate jdbcTemplate;
public void bulkSave(List<Book> books) {
String sql = "INSERT INTO book " +
"(title, content, writer, created_at) VALUES (?, ?, ?, ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, books.get(i).getTitle());
ps.setString(2, books.get(i).getContent());
ps.setString(3, books.get(i).getWriter());
ps.setTimestamp(4, Timestamp.valueOf(books.get(i).getCreatedAt()));
}
@Override
public int getBatchSize() {
return books.size();
}
});
}
}
테스트 코드 또한 매우 간단했다.
@SpringBootTest
class BookRepositoryTest {
@Autowired
BookRepository bookRepository;
@Autowired
JdbcBookRepository jdbcBookRepository;
final int testLength = 300;
private List<Book> generateBookListLengthOf(int length) {
List<Book> bookList = new ArrayList<>();
for (int i=0; i<length; i++) {
bookList.add(MockBookGenerator.generate());
}
return bookList;
}
@Test
@DisplayName("jdbcTemplate 사용")
void jdbcTemplateBatchUpdateTest() {
long start = System.currentTimeMillis();
jdbcBookRepository.bulkSave(generateBookListLengthOf(testLength));
long end = System.currentTimeMillis();
System.out.println("Using JdbcTemplate");
System.out.println("end - start = " + (end - start) * 0.001 + " seconds");
}
@Test
@DisplayName("JPARepository의 saveAll 사용")
void saveAllTest() {
long start = System.currentTimeMillis();
bookRepository.saveAll(generateBookListLengthOf(testLength));
long end = System.currentTimeMillis();
System.out.println("Using JpaRepository.saveAll");
System.out.println("end - start = " + (end - start) * 0.001 + " seconds");
}
}
저장할 객체 개수를 testLength로 정해두고, 해당 개수만큼 Book 객체를 저장하는 작업에 걸리는 시간을 두 가지 레포지토리를 모두 사용하여 비교해보았다.
testLength는 우선 300개로 정해보았다.

첫 번째로 JdbcTemplate을 사용한 결과로, 0.108초의 시간이 소요된 것을 알 수 있다.

두 번째는 JpaRepository를 사용한 결과로 0.329초의 시간이 소요된 것을 알 수 있다.
수치상만 따져보면 약 세 배 정도가 차이난다고 말할 수 있지만, 데이터 자체가 그렇게 크지 않기 때문에 절대적인 시간만 따져보면 300개의 데이터 저장에 대해 JpaRepository를 사용한다고 해서 그렇게 큰 성능상의 이슈를 야기할 것 같진 않다.
수치를 확 높여서 testLength를 10000개로 다시 시도해보았다.
final int testLength = 10000;


기존 300개 때의 약 3배보다 10000개일 때 조금 더 큰 차이를 보였다.
저장해야 할 데이터가 늘어날수록 성능 차이가 조금씩 더 심해질 것이라고 예상해 1000개부터 10000개씩 1000 단위로, 10000개부터 100000개까지 10000 단위로 테스트하며 차이를 비교해보기로 했다.

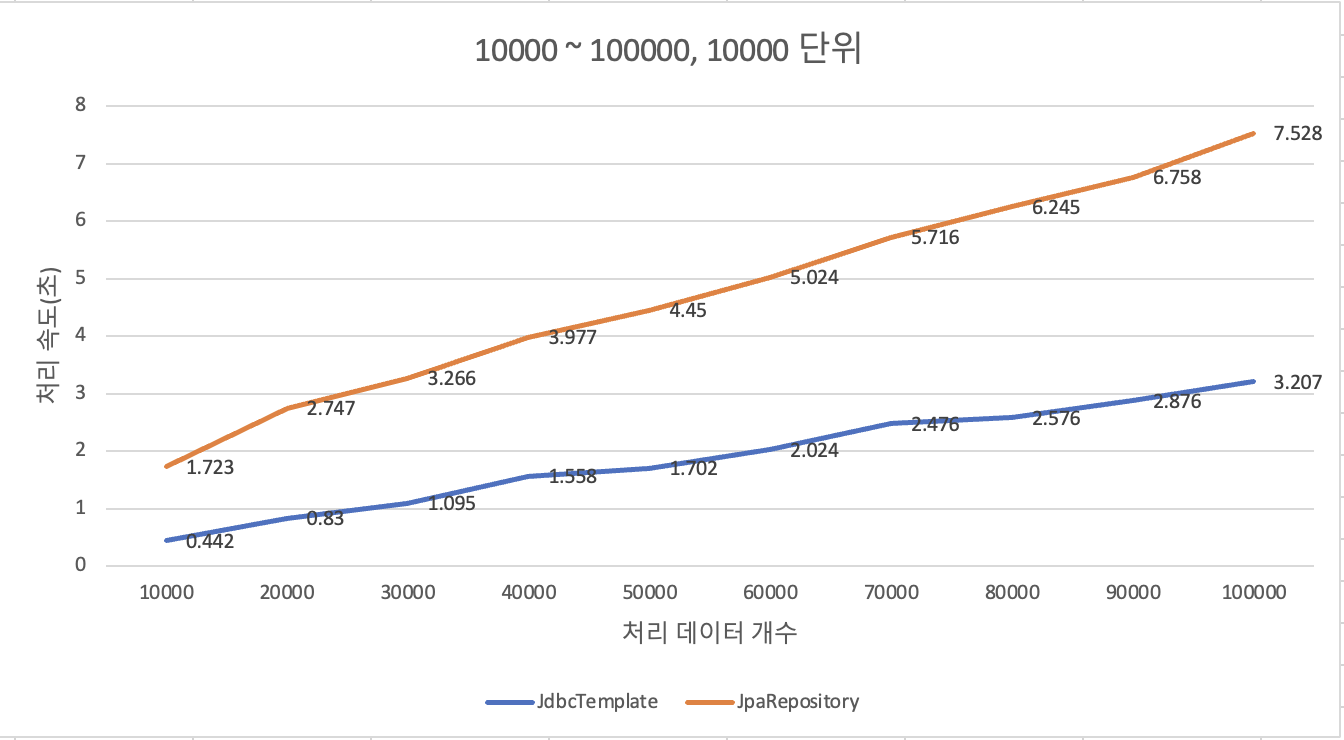
지수함수마냥 특정 개수부터 두드러진 차이가 발생하지 않을까 기대했는데, 100000건까지 살펴본 결과에 따르면 그 정도의 특이점은 없었다.
평균 증가율 또한 두 방식 모두 10 ~ 15퍼센트 사이로 유사한 모습을 보여주었다.
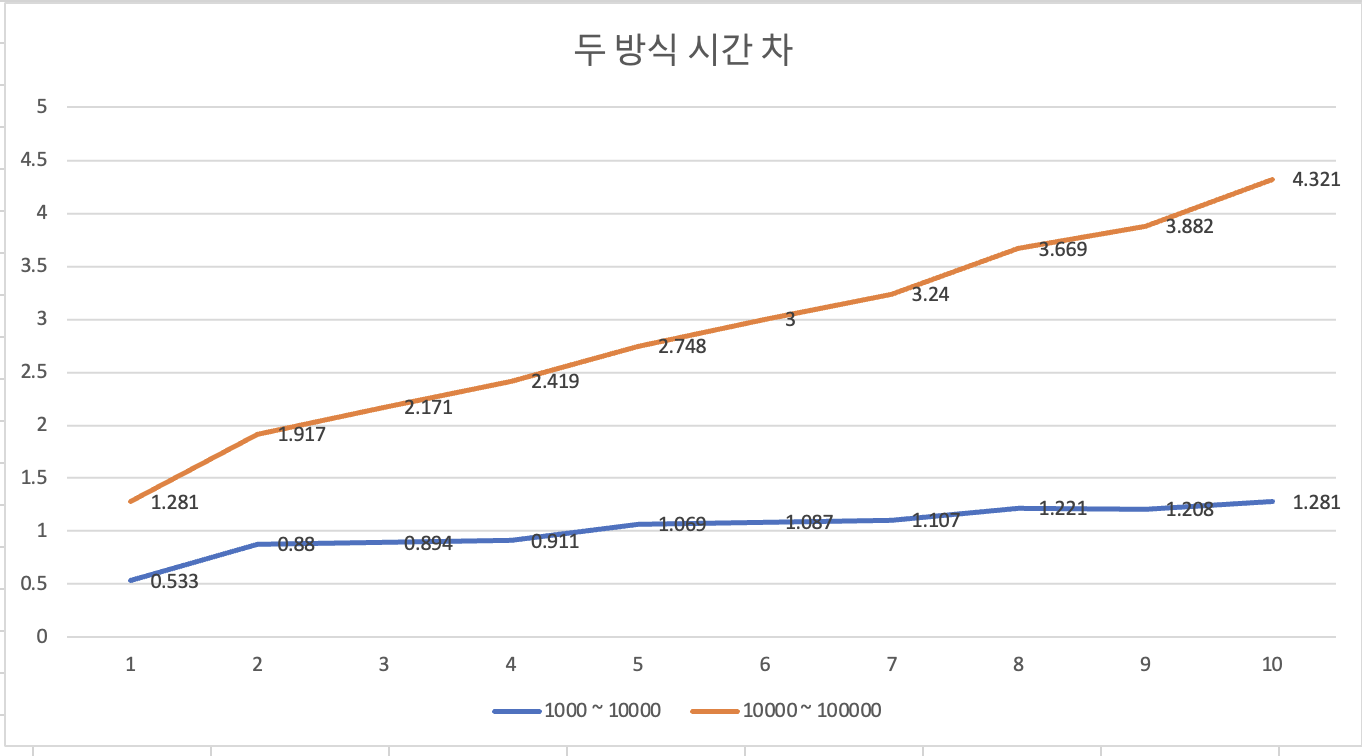
가장 중요한 두 방식의 시간차를 확인한 결과, 1000 ~ 10000건 사이의 데이터는 최대 1.2초 가량의 시간차가, 10000 ~ 100000건 사이의 데이터에서는 최대 4.3초 가량의 시간차를 보였다.
확실히 1초 이상의 시간차를 보이는 경우에는 JpaRepository를 그대로 사용하기는 상당한 부담이 될 것으로 보인다.
결론
bulk insert 작업 시, JpaRepository 보다는 JdbcTemplate을 사용하는게 성능상 확실히 좋다.
처리해야하는 데이터의 개수가 많아지면 많아질수록 더더욱 그러하다.
하지만, 데이터 수가 1000개 이하라면 절대적인 시간차는 미비한 수준이므로, TPS 등을 종합적으로 따져서 어떤 방식으로 bulk insert 작업을 처리할지 결정하면 될 것 같다.
작업의 효율성과 오버엔지니어링 사이의 균형을 적절히 유지하자.
+ 번외