
해시테이블이란?
해시테이블은 매우 빠른 평균 삽입, 삭제, 탐색연산을 제공하는 유용한 자료구조이다.
해시테이블은 데이터를 key - value 쌍으로 묶어 관리하는데, 국어사전이 낱말들을 적어놓은 방식과 유사하다.
국어사전에서 낱말을 찾아보면, 하나의 낱말에 하나 혹은 이상의 설명들이 적혀있다.
이 때, 낱말을 key, 그에 대한 설명을 value라고 비유할 수 있다.
실제로 파이썬에서 제공하는 dictionary 자료가 대표적인 해시테이블 기반의 자료라고 할 수 있다.
해시테이블의 데이터 저장 방법
해시테이블은 일반적인 배열과는 다르게 자료들을 순차적으로 저장하는 것이 아닌 key값을 인덱스로 저장한다.
예컨대, key가 201503196에 value가 "홍길동"인 데이터를 저장하고자 한다면 0 ~ 201503197까지의 배열을 만들어 201503196위치에 데이터를 저장한다.
하지만, 이런식의 저장방식을 이용하면 한 개의 데이터를 저장하기 위해서 201503196 길이 만큼의 배열을 만들어야하고 고, 빈 메모리들은 그대로 낭비되므로 공간적 낭비가 매우 심하다.
따라서, 해시테이블은 이 과정에서 해시함수라는 것을 이용해 key 값을 처리해준다.
해시함수는 key값에 어떠한 일련의 과정을 취해서 키 값이 내가 원하는 범위안에 들어오도록 설정할 수 있도록 해준다.
예를 들어, h.f (hash function)을 key = key % 10 이라고 정의한다면, 201503196의 key는 6이 되는 것이다.
이렇게 되면 0 ~ 7 까지의 배열만 생성하면 되므로 공간의 효율성을 증진시킬 수 있다.
또한, key 값만으로 데이터를 가져올 수 있기 때문에 데이터를 탐색하는 데 O(1)만큼의 시간이 걸린다.
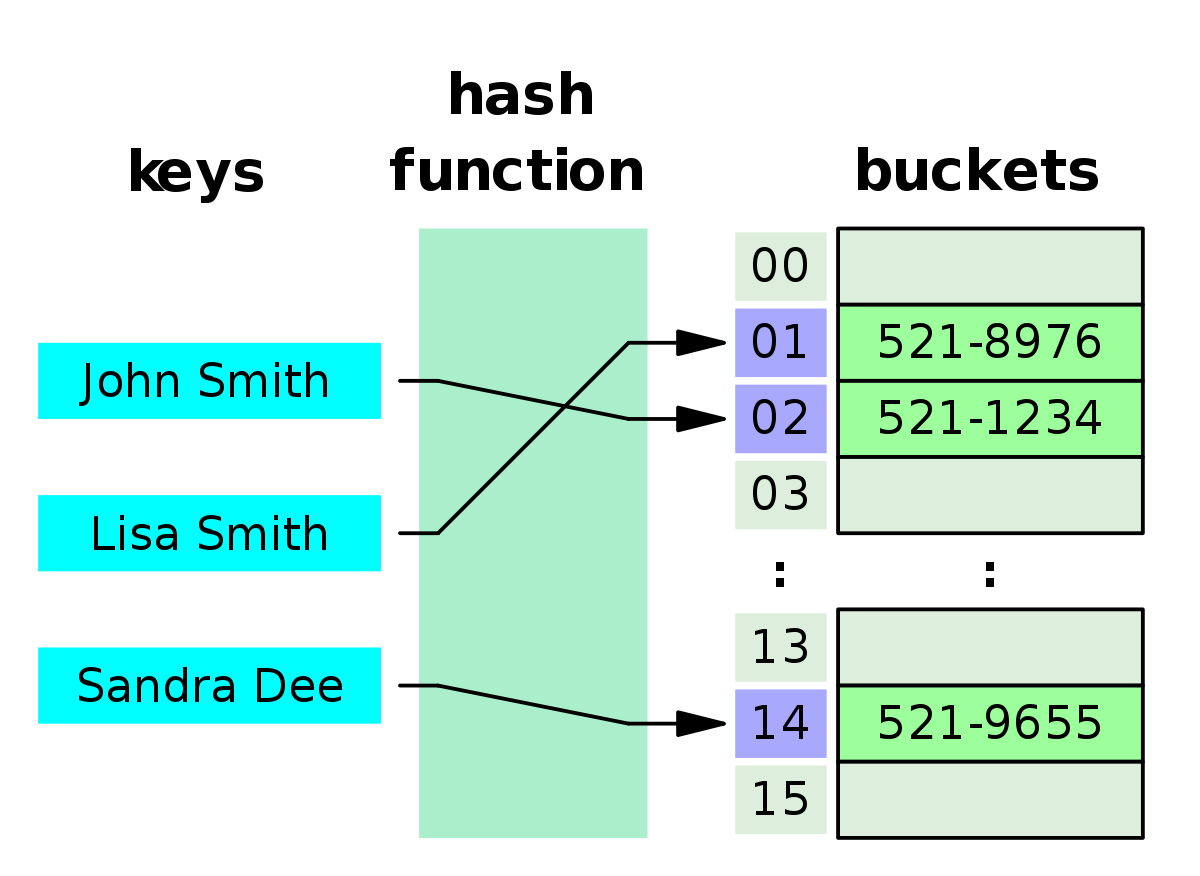
해시테이블의 충돌
만약 201503196 과 201394826이라는 서로 다른 키 값을 가진 각각의 데이터가 저장된다고 생각해보자.
두 키 값은 모두 해시함수를 거쳐 6이라는 키값을 갖게 된다. 즉, 테이블에 저장될 위치가 동일해지게 되는 것이다.
이것을 보고 충돌(collision)이 발생했다고 말한다.
해시함수는 완벽하지 않기 때문에, 불가피하게 충돌이 발생할 수 밖에 없으며 이러한 충돌을 잘 해결하는 것이 중요하다.
해쉬테이블의 충돌을 해결하는 방법(Collision resolution method)에는 대표적으로 2가지가 있는데, 이 부분은 다음 글에 포스팅 하겠다.
'그 외 공부 > 자료구조' 카테고리의 다른 글
| 해시테이블의 충돌방지 - Open Addressing (0) | 2021.01.15 |
|---|---|
| 해시테이블의 충돌해결 - Chaining 방식 with 파이썬(Python) (0) | 2021.01.12 |
| 더블리 링크드 리스트의 구현 및 연산, 링크드 리스트와의 차이점 - 파이썬 (Python) (0) | 2021.01.11 |
| 링크드 리스트의 구현 및 연산 - 파이썬(Python) (0) | 2021.01.11 |
| 링크드 리스트(연결 리스트), 그리고 배열과의 차이점 (0) | 2021.01.11 |