![]()
힙이란? 힙은 트리 형태로 만들어진 자료구조 중 하나이다. 힙은 트리 중에서도 두 가지 조건을 만족해야 하는데, 첫 번째는 완전이진트리여야 한다는 것 두 번째는 부모 노드의 값이 항상 자신의 자식노드들보다 커야한다는 것이다. (힙의 예시) 위 트리는 트리의 높이 - 1 까지 모두 빈 노드 없이 차 있으며 마지막 높이의 데이터들 역시 왼쪽부터 오른쪽으로 차례대로 채워져있으므로 완전이진트리의 속성을 만족시킨다고 할 수 있다. 또한, 모든 노드들이 자신의 자식노드들보다 큰 값을 가지기 때문에 힙의 성질 역시 만족시킨다고 할 수 있겠다. 힙 자료구조의 구현 힙 자료구조는 기본적으로 완전이진트리이기 때문에, 특정 노드의 위치를 알면 그 노드의 부모 노드의 위치와 두 자식 노드의 위치를 알 수 있다. 이를 활용하면..
![]()
1) 이진트리 이진트리는 부모 하나 당 최대 2개까지의 자식노드를 가질 수 있는 트리를 말한다. 따라서 이진트리의 각 노드 인스턴스는 자신의 부모 노드에 대한 레퍼런스와 두 자식노드에 대한 레퍼런스를 가지게 된다. 이진트리의 노드 클래스를 구현하면 다음과 같다. # 이진트리의 노드 class Node: def __init__(self, data): # 파라미터로 받은 데이터를 삽입 self.data = data # None으로 초기값을 지정 후, 노드 생성 후에 지정 self.left_child = None self.right_child = None 이후, 각 데이터를 담은 노드 클래스를 만들어주고 자식 관계를 설정해주고 나면 노드를 통해 그 노드의 부모노드와 자식노드를 모두 호출할 수 있게 된다. 2)..
문제 (링크) https://www.acmicpc.net/problem/1463 1463번: 1로 만들기 첫째 줄에 1보다 크거나 같고, 106보다 작거나 같은 정수 N이 주어진다. www.acmicpc.net 나의 풀이 n = int(input()) d = [0] * 1000001 for i in range(2, n+1): d[i] = d[i-1] + 1 if i % 2 == 0: d[i] = min(d[i], d[i//2] + 1) if i % 3 == 0: d[i] = min(d[i], d[i//3] + 1) print(d[n]) 나동빈님의 유튜브 이.코.테 다이나믹 프로그래밍 강의를 들은 후 연습 문제로 풀어보았다. 사실 유튜브에서 제공한 연습문제랑 연산 조건만 다를 뿐 아예 같은 문제라고 봐도 ..
문제 (링크) https://www.acmicpc.net/problem/1978 1978번: 소수 찾기 첫 줄에 수의 개수 N이 주어진다. N은 100이하이다. 다음으로 N개의 수가 주어지는데 수는 1,000 이하의 자연수이다. www.acmicpc.net 나의 풀이 n = int(input()) data = list(map(int, input().split())) count = 0 for x in data: for i in range(2, x+1): if x % i == 0: if x == i: count += 1 break print(count) 백준에서 틀린 문제를 살펴보다가 발견한 문제다. 왜 그랬는지는 모르겠는데 꽤 많이 틀려놨었고, 발견하자마자 풀어봤는데 바로 풀렸다. 알고리즘 문제 중 소수와..
문제 (링크) https://www.acmicpc.net/problem/1920 1920번: 수 찾기 첫째 줄에 자연수 N(1 ≤ N ≤ 100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], …, A[N]이 주어진다. 다음 줄에는 M(1 ≤ M ≤ 100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들 www.acmicpc.net 나의 풀이 from sys import stdin n = stdin.readline() # 이진탐색을 진행해야하므로 탐색을 할 리스트를 sorted 처리 해준다 group_n = sorted(list(map(int, stdin.readline().split()))) m = stdin.readline() group_m = list(map..
![]()
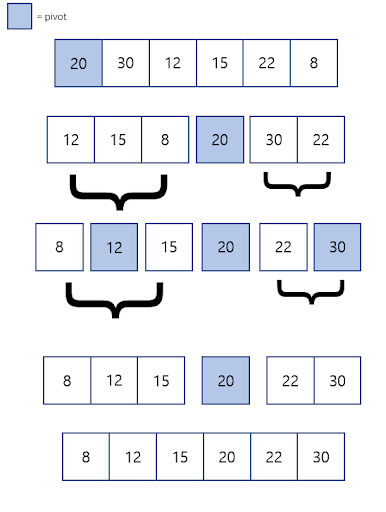
대부분의 프로그래밍 언어에 내장된 정렬 함수들은 이 퀵 정렬 알고리즘과 병합 알고리즘을 기반으로 만들어졌다. 그 중 하나인 퀵 정렬 알고리즘에 대해 학습해보자. 선택 정렬, 삽입 정렬이 데이터들을 순차적으로 비교하는 것과 다르게, 퀵 정렬 알고리즘에선 기준 데이터(Pivot)를 설정해 해당 값보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방식으로 정렬을 수행한다. 퀵 정렬 알고리즘이 작동하는 방식의 순서도는 다음과 같다. 1. 비교 기준이 될 pivot 인덱스를 설정한다. (기본적인 퀵 정렬 알고리즘에선 배열의 맨 처음 값을 pivot으로 설정한다.) 2. arr[pivot]부터 왼쪽부터 +1 씩 순차적으로 이동하며 arr[pivot]보다 큰 값을 찾는다. 3. 배열의 맨 뒤 값부터 순차적으로 -1 씩 ..
![]()
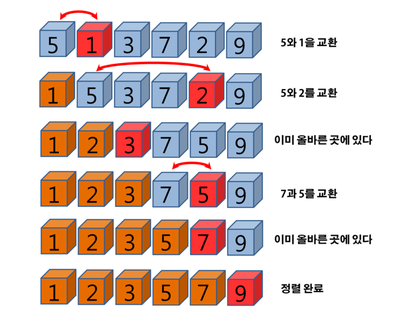
정렬 알고리즘은 값들을 특정 조건에 따라 정렬하기 위해 사용되는 알고리즘이다. ex) 오름차순, 내림차순 대부분의 언어들에서는 원소들을 정렬하는 내장함수들이 존재하기 때문에 자연스럽게 그 함수들을 사용하지만, 당연히 이 과정은 자동으로 이루어지는 것이 아니라 내부적으로는 일련의 과정들을 거친다. 선택 정렬 알고리즘 선택 정렬 알고리즘은 수 많은 정렬 알고리즘 중 하나이다. 선택 정렬 알고리즘의 아이디어는 그림과 같이, 첫 번째 값부터 맨 마지막 값까지 쭉 돌면서 가장 작은 값들을 하나씩 배열의 맨 앞으로 가져오는 것이다. 파이썬을 통해 구현한 선택 정렬은 다음과 같다. arr = [5, 10, 9, 33, 21, 7, 2, 3, 0] # 정렬되지 않은 array for i in range(len(arr)..
문제 (링크) https://www.acmicpc.net/problem/2178 2178번: 미로 탐색 첫째 줄에 두 정수 N, M(2 ≤ N, M ≤ 100)이 주어진다. 다음 N개의 줄에는 M개의 정수로 미로가 주어진다. 각각의 수들은 붙어서 입력으로 주어진다. www.acmicpc.net 나의 풀이 from collections import deque n, m = map(int, input().split()) graph = [] # 상 하 좌 우 dx = [-1, 1, 0, 0] dy = [0, 0, -1, 1] for _ in range(n): graph.append(list(map(int, input()))) def bfs(x, y): queue = deque() queue.append((x, ..